1、论文参考:
2.目录
1.attention机制介绍
当我们在处理的数据是不等长序列的时候,我们需要考虑如何处理如何去获得其有效的语义信息,举个例子,传统的rnn模型存在梯度消失、梯度爆炸,而改良的基于门控单元lstm和gru,虽然缓解了长文本带来的影响,但仍然不能解决实际问题。
自注意力机制要解决的问题是:当神经网络的输入是多个大小不一样的向量,并且可能因为不同向量之间有一定的关系,而在训练时却无法充分发挥这些关系,导致模型训练结果较差。
2.输入的seq to vector
由于输入的序列不能被计算机直接处理,所以需要转化成向量的形式。
-
one-hot encording
能表示序列不能表达语义。
-
word embedding:
- 静态词向量 word2vec :将一个词在整个语料库中的共现上下文信息聚合至该词的向量表示中,也就是说,对于任意一个词,其向量表示是恒定的,不随其上下文的变化而变化。
- 动态词向量 BERT ELMO:动态词向量指的会根据上下文动态适应性的调整词向量,可以一定程度上解决单词多意性。
3.Self-attention(seq one2one )
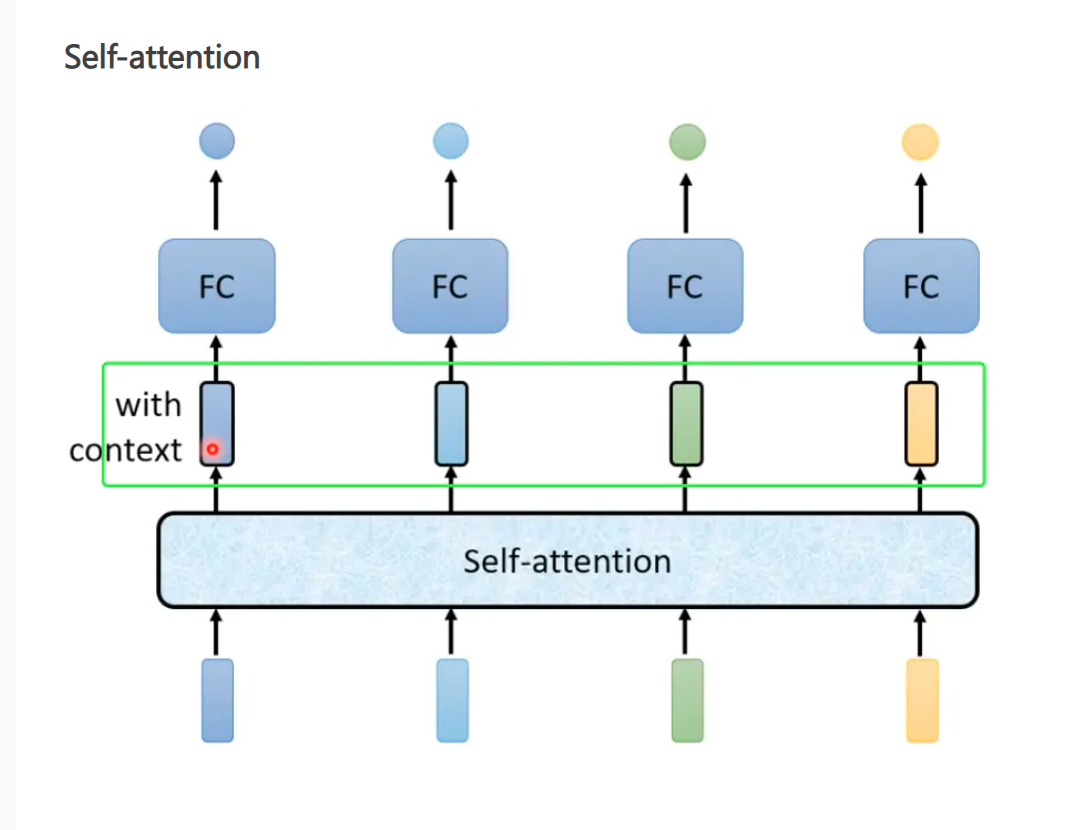
4.self.attention 中的Q,K,V
Self-attention最核心的数学公式:键值对注意力。通过计算Q,K,V进而获得其注意力分数
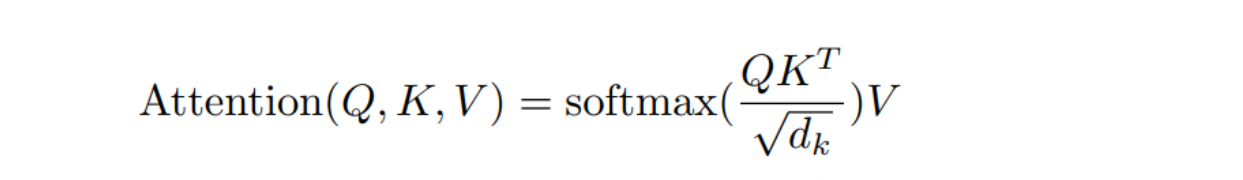
ps:
个人理解 注意力分数,可以看成是在一个序列中每个向量和其他向量的相似度。 上面公式的核心在于
三个矩阵QKV的计算,而QKV是输入的向量和三个可学习权重矩阵相乘得到不同矩阵(后面会讲QKV是怎么来的),把上面的公式看成(A * At)* A(t代表转置) 那么问题来了 一个矩阵和自身转置矩阵相乘得出的东西是啥,如果有线性代数基础的可能会清楚,其实这就是在求向量的内积。 而向量的内积几何意义就是投影。其几何公式和余弦相似度有点相关

当内积值为正值时,两个向量大致指向相同的方向(方向夹角小于90度),当内积值为负值时,两个向量大致指向相反的方向(方向角大于90°)。当内积值为0时,两个向量互相垂直。
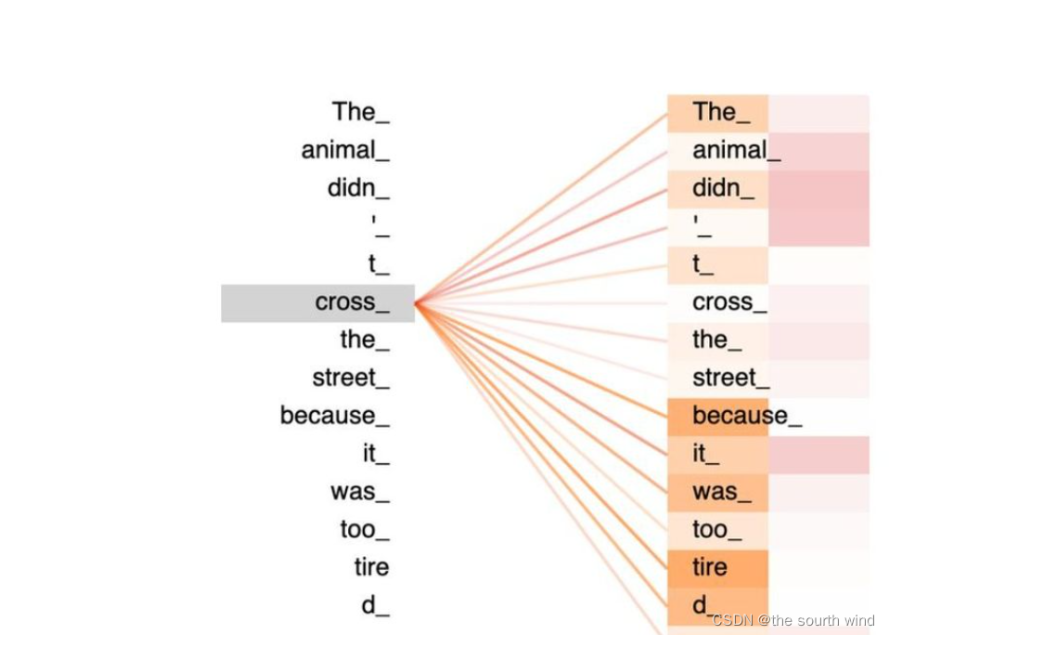
(A * At)所以现在能明白矩阵*矩阵转置的意义了吧,其结果每个向量与自己和其他向量进行内积运算的结果。那么下面问题来了 为啥 还需要 再 * A矩阵,是因为通过其内积使原来的向量变成带有注意力机制的新向量。下图所示。如果没看懂也没关系,就一句话(相关度其本质是由向量的内积度量的)
5 Q K V 矩阵
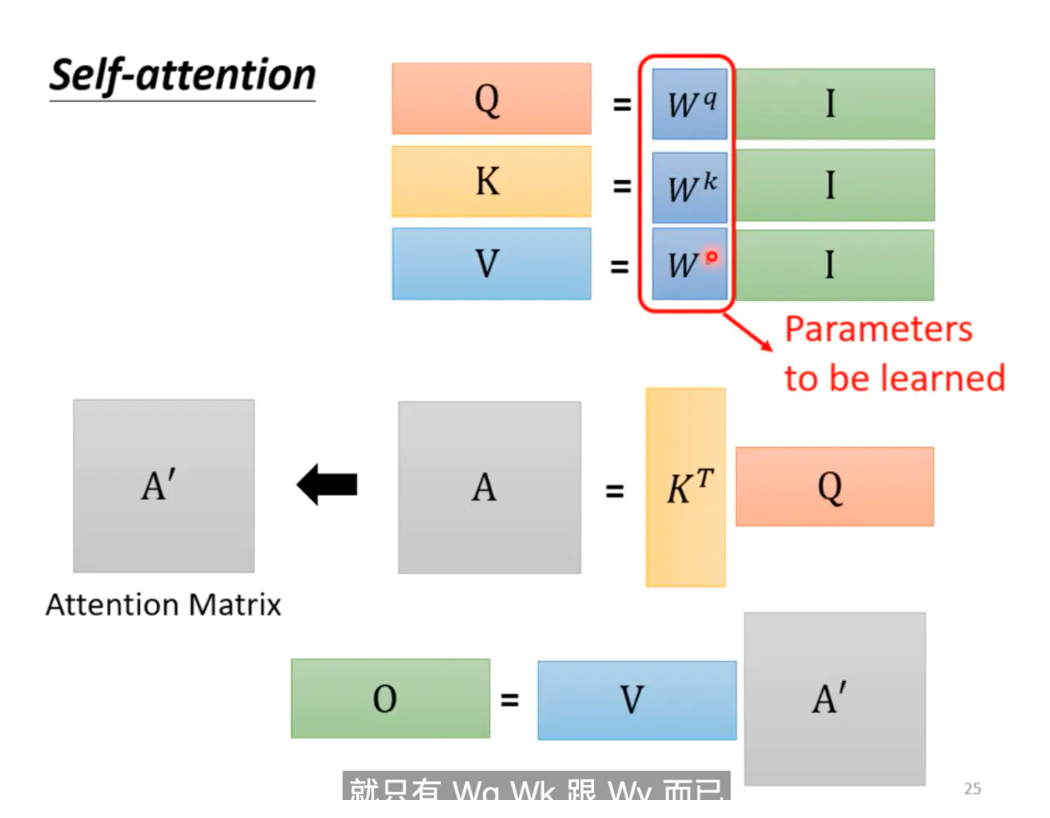
上述过程就是 self Attention计算过程以及Q、K、V的矩阵生成。
6.多头注意力机制
多头注意力机制,就是多套qkv三个矩阵,从而映射到多个不同的向量空间,进而更好的去表示每个字之间的相关度。在最后一层拼接起来 形成output。
7 CNN & RNN VS Self-attention
-
CNN 和Self-attention

CNN:平移不变性与归纳偏置 Attention:长范围关系的建模能力
CNN:不断通过卷积感受野
Attention:一次就获得全部的感受野
来自实验室大师兄 侯立师兄
-
RNN vs Self-attention
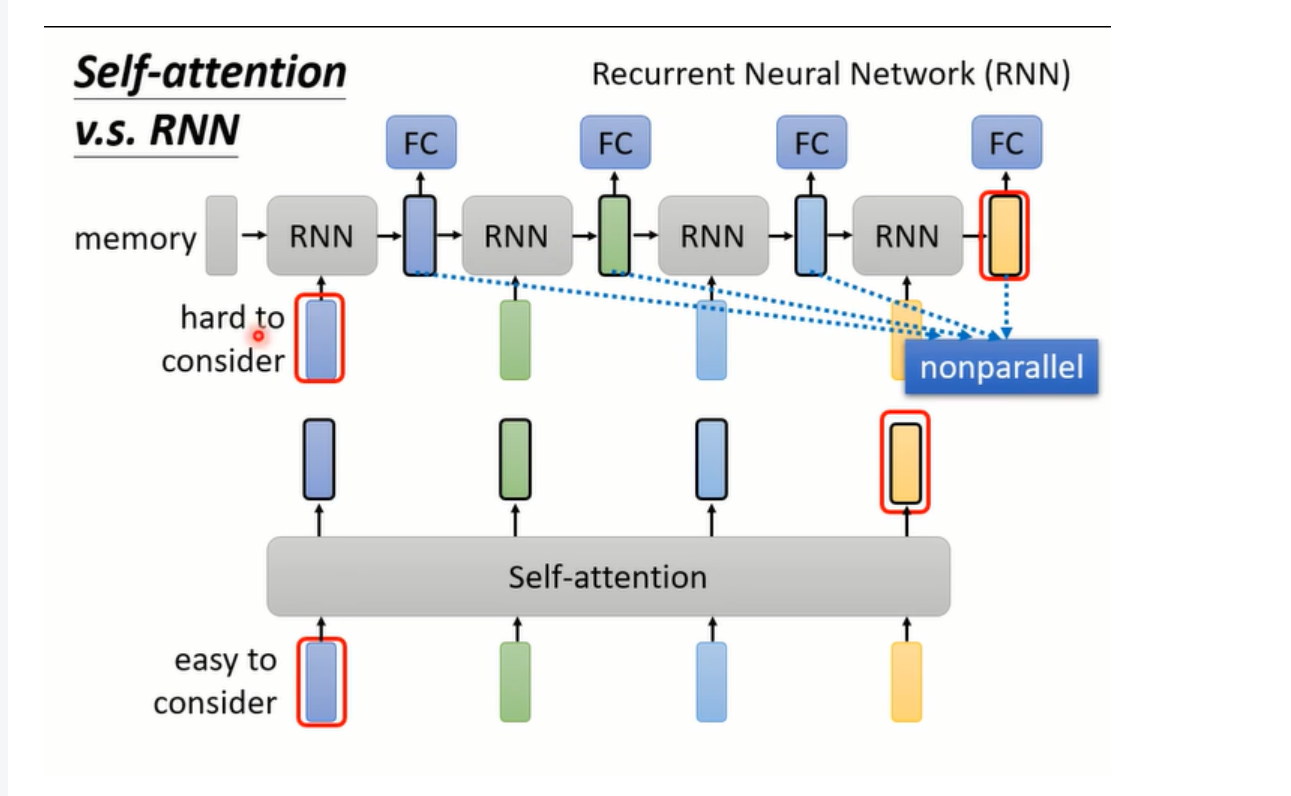
RNN由于其模型架构隐藏层只能通过上一个传到下一个,无法并行处理,Self-attention可以并行化输出
RNN当结果要考虑比相对较远输入的位置时,容易梯度爆炸和梯度消失,Self-attention可以很好的对输入位置比较远的向量进行考虑,因为其每个向量的距离都是一样的。
结语
励志做一个有梦想的NLPer
坑坑 加油