TextCNN学习
参考论文:
参考网站:
目录:
一:TextCNN 简介:
TextCNN的实现原理比较简单,输入数据首先通过一个embedding layer,得到输入语句的embedding 的表示,然后通过卷积、激活、最大池化,将所得到的值concat起来,最后通过一个fully connected layer得到最终的输出,整个模型的结构如下图:

模型输入的Shape Analyse:
数据预处理:数据同一处理成相同的长度的大小(填补与截断的方式):seq_len。
-
输入句子:[batch_size,seq_len]
-
经过embedding层:[batch_size,seq_len,embed_size]
-
升维:xxxx.unsqueeze(1) [batch_size, channel(=1), seq_len, embed_size]
-
卷积操作(假设多个卷积核(2,3,4)) 每个有256个:
[batch_size,256,seq_len-2+1]
[batch_size,256,seq_len-3+1]
[batch_size,256,seq_len-4+1]
-
最大池化:
[batch_size,256]
[batch_size,256]
[batch_size,256]
-
concat拼接:
[batch_size,256*3] 按照dim=1堆叠
-
全连接(num_class 分类数)
[batch_size,num_class]
-
softmax 归一化:
从将fc的数据通过softmax归一化,取最大概率的数作为分类
调参策略:
- 将原始文本转化成词向量的过程:静态词向量word2vec<动态词向量BERT.
- 卷积核大小:文本越长,核大小越大,但其所通过卷积获取语义更粗粒度。
- 激活函数采用ReLU和tanh
- dropout
案例 代码:
1.导入相关的库和包
import torch
import numpy as np
import torch.nn as nn
import torch.optim as optim
import torch.utils.data as Data
import torch.nn.functional as F
dtype = torch.FloatTensor
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
sentences = ["i love you", "he loves me", "she likes baseball", "i hate you", "sorry for that", "this is awful"]
labels = [1, 1, 1, 0, 0, 0]
embedding_size = 2
sequence_length = len(sentences[0])
num_classes = len(set(labels))
batch_size = 3
word_list = " ".join(sentences).split()
vocab = list(set(word_list))
word2idx = {w:i for i,w in enumerate(vocab)}
vocab_size = len(vocab)
sentences = ["i love you", "he loves me", "she likes baseball", "i hate you", "sorry for that", "this is awful"]
labels = [1, 1, 1, 0, 0, 0]
embedding_size = 2
sequence_length = len(sentences[0])
num_classes = len(set(labels))
batch_size = 3
word_list = " ".join(sentences).split()
vocab = list(set(word_list))
word2idx = {w:i for i,w in enumerate(vocab)}
vocab_size = len(vocab)
input_batch,target_batch = make_data(sentences,labels)
input_batch,target_batch = torch.LongTensor(input_batch),torch.LongTensor(target_batch)
dataset = Data.TensorDataset(input_batch,target_batch)
dataloader = Data.DataLoader(dataset,batch_size,shuffle=True)
2.网络模型TextCNN
class TextCNN(nn.Module):
def __init__(self):
super(TextCNN,self).__init__()
self.wordembedding = nn.Embedding(vocab_size,embedding_size)
output_channel = 3
self.conv = nn.Sequential(nn.Conv2d(1,output_channel,(2,embedding_size)),
#inpu_channel, output_channel, 卷积核高和宽 n-gram 和 embedding_size
nn.ReLU(),
nn.MaxPool2d((2,1)))
#长:(图像尺寸-卷积核尺寸 + 2*填充值)/步长+1 宽:(图像尺寸-池化窗尺寸 + 2*填充值)/步长+1
self.fc = nn.Linear(output_channel,num_classes)
def forward(self,X):
"""
X :[batach_size,seq_len]
"""
batch_size = X.shape[0]
embedding_X = self.wordembedding(X)
embedding_X = embedding_X.unsqueeze(1)
conved = self.conv(embedding_X)
flatten = conved.view(batch_size,-1)
out = self.fc(flatten)
return out
3.定义loss & 优化器
model = TextCNN().to(device)
criterion = nn.CrossEntropyLoss().to(device)
optimizer = optim.Adam(model.parameters(),lr=1e-3)
4.train
for epoch in range(5000):
for batch_x,batch_y in dataloader:
batch_x,batch_y = batch_x.to(device),batch_y.to(device)
pred = model(batch_x)
loss = criterion(pred,batch_y)
if (epoch + 1) % 1000 == 0:
print('Epoch:', '%04d' % (epoch + 1), 'loss =', '{:.6f}'.format(loss))
#三件套
optimizer.zero_grad()
loss.backward()
optimizer.step()
5.predict
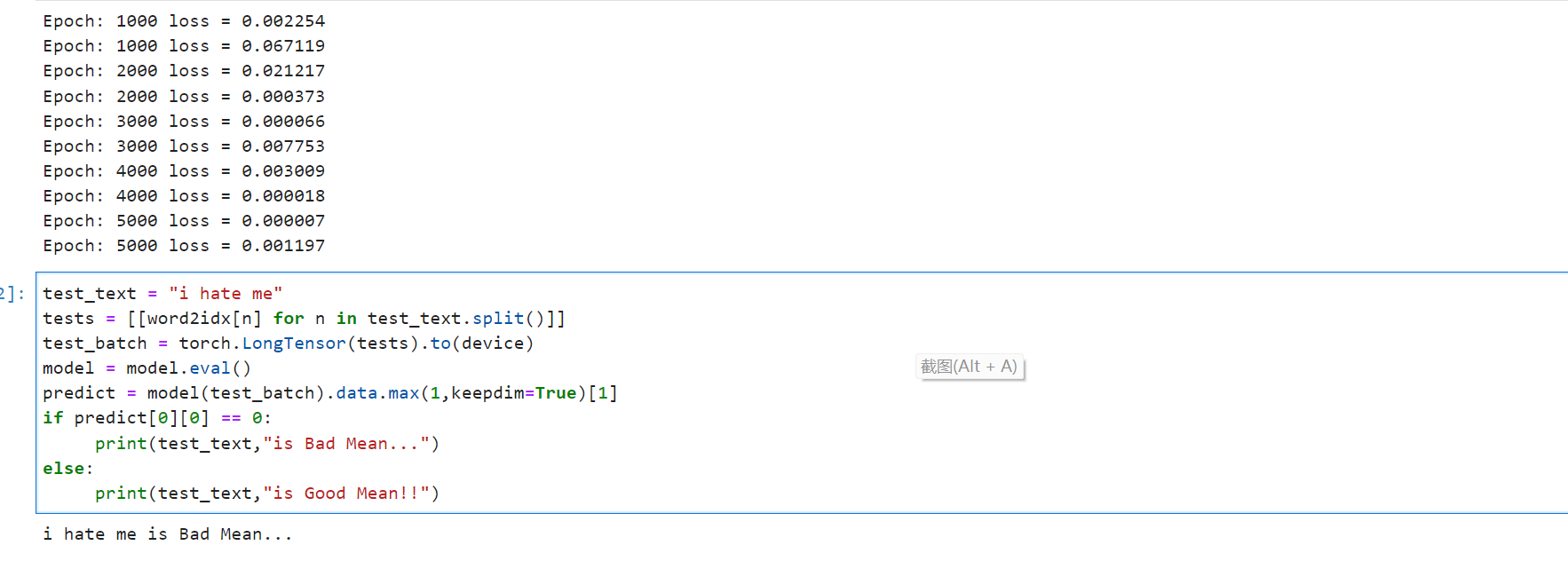
test_text = "i hate me"
tests = [[word2idx[n] for n in test_text.split()]]
test_batch = torch.LongTensor(tests).to(device)
model = model.eval()
predict = model(test_batch).data.max(1,keepdim=True)[1]
if predict[0][0] == 0:
print(test_text,"is Bad Mean...")
else:
print(test_text,"is Good Mean!!")
6.result
结语
励志做一个有梦想的NLPer
坑坑 加油